Indiana University — Jacobs School of Music
B.S. Recording Arts with Computer Music concentration. Music Faculty Award scholarship recipient. IU Jacobs is consistently ranked among the top music programs in the country.
Curriculum: studio engineering (Pro Tools, signal flow, microphone technique) plus computer music (SuperCollider, algorithmic composition, real-time synthesis, audio programming).
The key insight: audio engineering is a software engineering problem. Signals are data. Studios are systems. Mixes are algorithms.
Electroacoustic Free Improvisation

Music project focused on achieving musical transcendentalism through DSP, neural networks, and free software. First release November 2010.
Core concept: real-time AI accompaniment for solo instrumentalists. Live signal processing and algorithmic response—not backing tracks.
Recognition: Runner-up at SEAMUS (Society for Electroacoustic Music in the US) 2010 summer festival, University of Miami.
Collaborators: Garrett Semmelink (violin, percussion, melodica) — 30+ compositions. Tyler Dinner (guitar). Max Pena (guitar). Cosmo D (cello). Myself on synthesis.
Infrastructure: jekyll-hypermusic framework powers multipli.city. Auto-generated podcast feeds, HyperMusic licensing. All releases free to download. Catalog spans 2010–2023.
Audiobooks, QC Automation, and a Patent
Audible, Inc., Newark, NJ. Started as Post-Production Associate. Promoted to ACX Production Coordinator within two years.
Managed team of 3 audio QA engineers. Scaled production from 200-300 audiobooks/month to 3,000+/month in six months. Built the automated audio QC service that remains in use at Audible today.
US Patent #9412395 — "Narrator selection by comparison to preferred recording features." Extracts vocal characteristics (spectral features, prosodic patterns, formants, cadence, accent, timbre) using Fourier transforms, GMMs, and neural networks. Publishers specify weighted preferences; algorithm returns ranked matches. Inventor; patent owned by Amazon.
SpokenLayer, CBS, Littlstar
SpokenLayer — Audio Scientist. Spoken-word content analysis and processing at scale.
CBS/Showtime — Senior Business Analyst. Digital video strategy.
Littlstar — Lead Media Engineer (2016), then Director of Media Technology. VR/360° video delivery infrastructure, spatial audio. Deployed Ara.one (ARA), an Ethereum mainnet token for decentralized content distribution.
Notable projects: Papa Roach "Sound of Silence" music video premiere, Redfoo music video, theatrical VR premieres for *It*, *Paranormal Activity*, and other major studio franchises. Worked with most major film and TV studios.
Speaking: Bitmovin future of video codecs panel. Sennheiser audio forums on ambisonics and spatial audio.
Little Core Labs / MediaXML — XML processing library for media formats (RSS, mRSS, CableLabs ADI, XMLTV). Unified API for broadcast and streaming metadata.
Distributed P2P Video Transcoding
Peer-to-peer video transcoding framework. Developed as part of the Ara.one (ARA) token ecosystem at Littlstar.
Architecture: Hosts create transcoding pools. Participants join via discovery keys. Video segments distributed across peers, encoded in parallel, reassembled.
Incentive model: BitTorrent-style. Contribute encoding work, receive early access to finished content.
Stack: FFmpeg (encoding), Noise Network (encrypted P2P), CFS (distributed file storage). GUI for Windows 10, CLI for other platforms.
Partnership with Intel and Microsoft. Code cannot be released due to UWP platform discontinuation.
Lead Engineer — Distributed Audio Platform
Lead Engineer at Storyboard. Built distributed audio platform for decentralized content creation.
Wavecore — P2P audio library on Hypercore v10. Version control for audio: branch, merge, replicate across peer network.
Storyboard Platform — 40+ modules: data layers, playback engines, processing pipelines, mobile apps. Vue 3 frontend, AWS Lambda backend, AudioWorklets for browser-based DSP.
little-media-box — Audio-focused fork of Little Core Labs work. Resource-pool architecture for user-generated audio.
Low-Latency Linux and Differentiable Audio DSP
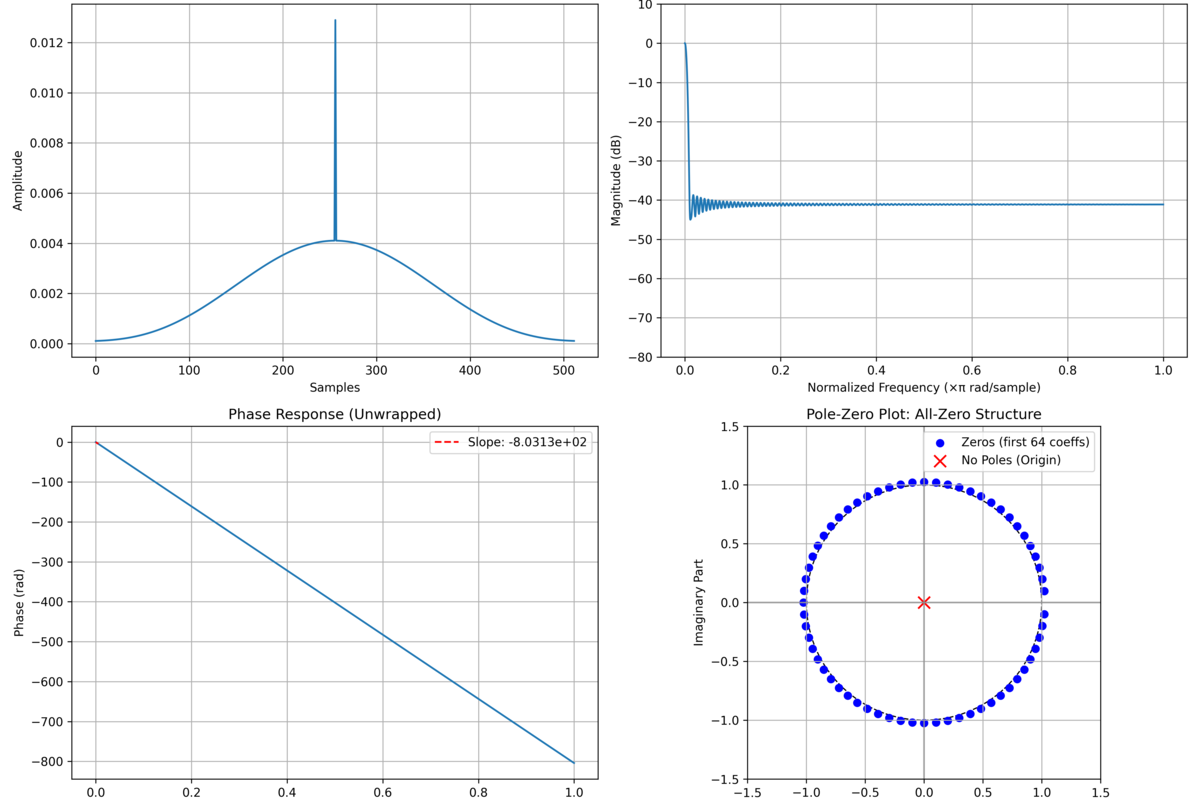
Novel audio DSP research and system configurations:
PRISM — First fully differentiable production audio limiter. Computes exact analytical gradients through DSP algorithms (peak detection, soft-knee compression, exponential smoothing) directly in Rust—not approximations or finite differences. Two-phase optimization: Phase 1 achieves LUFS targets via pre-gain, Phase 2 minimizes intermodulation distortion via stem gains. Can learn traditionally static parameters (attack, release, threshold, makeup gain) through gradient descent. O(n) recursive gradient algorithms. PyTorch-Rust integration via custom autograd. 20× realtime performance, 8.3dB IMD improvement over manual mastering. Opens the door to fully differentiable mixing consoles and effects chains.
hdspmixer-slint — Linux mixer control for RME HDSP/HDSPe interfaces. Rust rewrite replacing legacy FLTK with Slint UI.
nix-lowlatency — NixOS configuration for low-latency audio production. USB 2.0 audio at 48kHz, 64-bit float, real-time kernel, zero xruns.
Founder — Creator Platform

Content creator platform. Sole owner and operator.
Components: - tube.sh.upload — Multi-platform publishing (YouTube, Spotify, SoundCloud, Rumble) - tube.sh.live — Live streaming with multi-casting and chat - tube.sh.archive — Content archival with transcripts and metadata - tube.sh.feed — Self-hosted RSS with free/paid content separation - tube.sh.fans — Patron accounts and subscription tiers - tube.sh.translate — Captions in 120+ languages
Stack: Next.js 15, React 19, Supabase, Cloudflare Workers, PeerTube, Owncast.
Current scale: 3 platform clients, ~11-12 hours daily live content. Clients include Part of the Problem, Gas Digital, Rob Bernstein Comedy.
MCP Servers and AI-Native Audio Tools
AI tooling for audio production and accessibility:
carla-mcp-server — Claude integration with professional audio plugins. Natural language control of VST/LV2 plugins.
supercollider-mcp — AI agent interface for SuperCollider. Algorithmic composition and synthesis.
AVCP — Audio Vibecoding Coordination Protocol. Multiplayer AI-assisted mixing with safety gates for destructive operations.
t140llm — Real-time LLM streaming via ITU-T T.140 protocol for assistive technologies.
assistive-llm — Accessibility service for AI output. Screen reader compatibility for Claude responses.
FarmAssist — Homesteading assistant for Tennessee Zone 7a. Weather integration, livestock management, soil analysis.
Tennessee — Consulting and New Projects
Based in Tennessee. Active consulting: Parts Order, Horizon3 Venture Studios, Rumble CDN. Roles: Senior Backend Engineer, Audio/Telephony Consultant, Senior Systems Engineer.
Current projects: - inbox.audio — Email-to-audio summarization - pvp.codes — Pair Vibecoding Protocol for collaborative AI development - ChatKit — iOS audio messaging with real-time Whisper transcription
Core Beliefs
Audio as Data
Sound is information. Waveforms are data. I've been treating mixes as software systems since Indiana.
Distributed by Default
Centralized platforms are single points of failure—for creators, for culture, for freedom. P2P isn't just technology; it's politics.
Accessibility as Architecture
T.140 protocols, screen reader compatibility, assistive LLMs. If your technology excludes people, your technology is broken.
AI as Collaborator
Not replacement, not automation. The tool should handle what you can't, not pretend to be you.
Open Source as Obligation
The audio industry runs on proprietary black boxes. Every open-source audio tool is an act of democratization.
Creator Sovereignty
Your content, your audience, your revenue. Platforms should serve creators, not extract from them.
The Stack
// Audio & DSP
// Distributed Systems
// Languages & Frameworks
// AI & ML
The story continues.
Reach out if you want to work together.